
NVIDIA, Decoded: The Company Powering AI
The chips, the moat, the money, and the cracks. A field guide.


Source: Josh Edelson / Agence France-Presse/Getty Images
NVIDIA was always too early. Until it wasn’t.
Founded in 1993, the company wasn’t always a household name in AI. NVIDIA was originally founded to build graphics processing units (GPUs) that render images, videos, and 3D graphics for video games — tasks ill-suited for central processing units (CPUs) that execute instructions sequentially. While CPUs were great for rapid, complex, single-thread tasks, GPU architectures consisted of thousands of smaller cores that break data-heavy operations into tiny chunks to process them all in parallel, making GPUs far more efficient for processing gaming elements (e.g. pixels, textures, lighting) simultaneously. The same trait that made GPUs optimal for gaming workloads (parallel execution) made them solutions to any problem that could be solved in the same way.
In 2006, NVIDIA unveiled Compute Unified Device Architecture (CUDA): a proprietary programming model that allowed software developers to use GPUs for general-purpose compute for a broader set of applications (e.g. scientific research, medical imaging, geophysics, and cryptography). When CUDA launched, Wall Street didn’t understand the need. The stock languished for years as Wall Street viewed it as an expensive distraction to the core hardware business. People were questioning:
The market demand for general purpose computing done with GPUs.
Lack of performance portability (could only run NVIDIA chips), locking in developers to the company’s hardware, and
The ability for NVIDIA GPUs to be reliably adapted for heavy-duty scientific calculation, especially since it was so nascent and there were no mature debugging tools to troubleshoot workflows.
But there were other use cases for general-purpose compute with GPUs. And the ecosystem matured over time. After ‘Satoshi Nakamoto’ published the Bitcoin White Paper, crypto mining MOs quickly transitioned to GPUs, which delivered hash speeds up to 6x faster than with CPUs.
Researchers had also started experimenting with GPUs for deep-learning. The tipping point came in 2012, when AlexNet used NVIDIA GPUs to train an image-recognition system that crushed the field at the ImageNet computer vision competition. That moment convinced AI researchers of the need for GPUs and CUDA as the underlying foundation behind neural networks. With CUDA, researchers could easily write code directly to the GPU to manage data distribution across GPU memory and cores to maximize calculation speed.
In 2020, NVIDIA acquired Mellanox for $7B. Training AI models now required thousands of GPUs working together, sharing data at sub-millisecond latency; Mellanox’s networking technology helped these thousands of GPUs talk to each other at lightning speeds. The acquisition helped NVIDIA speed up data processing to optimize chip capabilities and transform itself into a GPU systems company.
NVIDIA stopped selling chips, and started selling AI factories: the GPUs and CPUs, the networking, racks, and software, all engineered as one machine. And because each piece runs best beside the others, each sale pulled in the next one.
NVDA 0.00%↑ is now a $5T+ company with AI as the largest tailwind. In 1Q27, ~$75B of the total $82B in quarterly revenue came from the Data Center segment (92%).

Data center compute is the heart of the business. The modern lineage started with Hopper in 2022 as the original workhorse chip that powered the first wave of AI models. BlackWell / Blackwell Ultra soon followed (started shipping January 2026), with Vera Rubin launching in 2H26 as a next generation chipset, consisting of a custom Vera CPU, main Rubin GPU and five supporting chips for networking, data movement, and security — all engineered to run as single supercomputer. NVIDIA claims it will deliver 5x the inference performance and 3.5x the training performance compared to Blackwell.
The Vera Rubin NVL72 rack will also break from past generations on physical design: it will be fully liquid-cooled and feature cable‑free modular tray designs, which Nvidia claims will cut installation times from two hours to five minutes vs. the Blackwell equivalent. The post-Rubin Kyber next-generation rack architecture wires together 576 GPUs (the NVL576) — a big jump from Blackwell’s 72. Rounding out the family is Rubin CPX, a lower-cost companion chip that uses cheaper memory and is aimed at certain inference jobs that make do with less.
NVIDIA’s roadmap points to Rubin Ultra in 2027, with more memory, and a Feynman generation in 2028 — the first to feature co-packaged optics to reduce the reliance on copper to transfer signals. The payoff is interconnect latency improvements, which especially matters as distances between installed clusters now climbs north of 10km+. Traditional copper-based methods make data transmission at high speeds difficult at these distances, making optics the primary and most practical means to transfer data in such cases.
More interestingly still is NVIDIA’s acquisition of Groq, which built a specialized chip, the LPU, to help accelerate inference speeds and eliminate run-time delays. It differs from GPUs in a few ways: the LPU stores model weights directly in massive on-chip SRAM to avoid off-chip memory / use of high-bandwidth memory (HBM). Second, it features a compiler that maps out exactly where every piece of data moves prior to execution vs. traditional hardware schedulers that manage at run-time. While NVIDIA’s GPUs are amazing at training models, they hit a wall for inference. Rather than compete with Groq, they paid $20B to license its technology and hire the top talent behind it. NVIDIA turned it into the LPX rack, a unit that sits next to the main Rubin racks and handles the fast-answer work, with the software then automatically deciding which chip does what.
On the software side, the foundational compute layer revolves around:
CUDA — NVIDIA’s core parallel computing platform and programming model that allows engineers to write code (C++ / Python) to GPUs to offload massive, heavy computation.
CUDA-X — a suite of >900 GPU-accelerated libraries, microservices and development tools built on top of CUDA to help developers build, optimize, and scale complex applications:
CUDA-X AI: deep learning + ML software stack for conversational AI, computer vision, and recommender systems. Key tools include TensorRT (SDK for inference).
CUDA-X Data Processing: tools to help accelerate data analytics / science ecosystem with RAPIDS (python libraries for performance gains), specialized math engines, and cuDF (for data processing).
CUDA-X HPC: a collection of compilers, libraries, tools, and APIs engineered for specific high-compute workloads (e.g. molecular dynamics, climate modeling, and financial forecasting).
In March 2026, NVIDIA launched Dynamo, an open source software to boost inference performance of the company’s GPUs by coordinating multiple servers to maximize token throughput while bringing both latency and costs down. Think of it as an orchestration layer that separates the prefill phase (processing user prompts to understand context) and decode phase (generating output tokens) onto different GPUs so that each process can be scaled and optimized independently. Dynamo helps maintain a map of past conversation memory across all relevant GPU clusters so that new requests are routed to the GPU that holds the required context memory, avoiding redundant computation. The software’s GPU scheduling capabilities also helps monitor wait times and processing loads to appropriately allocate resources automatically to meet demand in a cost-efficient way.
On the infrastructure management side, NVIDIA’s Run:ai is a kubernetes-native workload management and GPU orchestration platform that enables customers to pool fragmented GPUs across multi-cloud environments with dynamic GPU allocation, GPU virtualization, memory swapping, and governance.
For application development, NVIDIA also offers:
Omniverse — a Physical AI platform to help build applications, industrial digital twins, and robotics simulations; consists of a collection of APIs, microservices, and SDKs that allow developers to integrate real-time ray tracing, advanced physics, and interoperability into 3D production pipelines.
NeMo — an open-source suite of libraries and microservices to help developers build, monitor, and optimize AI agents. It consists of tooling for data preparation, model selection, agent building, and more.
Model Families:
Nemotron: family of multimodal foundation models spanning language, vision, reasoning, and speech for multi-step AI agents. Built for complex tasks (coding, scientific reasoning, and tool-calling) and omni-understanding (text, audio, image, video).
Cosmos: open-source platform consisting of world foundation models for Physical AI; models to help simulate / predict future states of physical environments, translate 3D simulations into photorealistic environments, and endow physical systems with vision-language intelligence.
Isaac GR00T - an open vision-language-action foundation model to bring generalized skills and reasoning to humanoid robots. The model uses a dual-system architecture: a fast-thinking action model to enable precise / continuous robot action, and a slow-thinking planning model to help robots make deliberate decisions about its environment.

The map above covers major pieces, but does not cover the whole of NVIDIA. The company has a hand in virtually every part of the AI ecosystem, from quantum computing tools and self-driving to recursive chip development. The larger pattern matters more than any single product: whether the job is rendering a video game or building humanoid robots, NVIDIA has positioned itself as the engine running beneath it all.
To gauge how large this company can get, it helps to split the question in two: the size of the market it sells into, and the size of the company itself.
On the most recent earnings call, CEO Jensen Huang projected that global AI infrastructure spending could reach $3-4T by the end of the decade. Sell-side forecasters, unsurprisingly, reach the same or higher territory: Goldman projects $7.6T in AI CapEx from 2026 to 2031 across compute, data centers, and power, with compute contribution as a % of total AI CapEx increasingly roughly 1% year. The annual outlay climbs from $765B in 2026 to $1.6T in 2031.
The caveat is how this capex is paid for. Much of it is financed by debt and complex off-balance sheet structures, with GPUs themselves sometimes being pledged as collateral. A slow down in AI demand or a drop in chip values would be felt quickly.

Source: Goldman Sachs
These numbers translate so well into NVIDIA’s top-line simply because of the assumption that NVIDIA maintains a strong and meaningful share of it over time. It is estimated that NVIDIA commands 80-90% of the AI accelerator and data center GPU market by revenue. But with players such as AMD, Google (TPUs), and Amazon (Trainium), most models assume NVIDIA market share dilution to ~70-75% over time. Even then, absolute revenue keeps rising because the pie is growing faster than any rival can eat into it. Jevon’s paradox is expected to add to that growth as cost reductions via efficiency gains lead to higher resource consumption / compute demand. Cheaper AI = more AI use.

NVIDIA’s market cap sits just over $5T, making it larger than the GDP of most countries, except the US, China, and Germany. Many still believe that NVIDIA has room to run, but the larger the company gets, the harder it is to digest the math behind the company doubling or tripling. A doubling of market capitalization implies adding another whole NVIDIA at the same multiple. The law of large numbers starts to look like a binding constraint, but if NVIDIA can maintain or take market share, $5T is just the tip of the iceberg.
The key forces driving the market and NVIDIA’s slice of it higher are:
The shift from training to inference. Early AI spending was all about teaching models. The bigger and more durable wave now is inference, the cost of running AI for billions of users daily, which scales with usage rather than with one-time builds. This is the difference between selling someone a textbook once and charging them every time they think.
Hyperscaler and sovereign spending. Most demand comes from a handful of giant buyers. The four largest cloud providers are set to spend around $700 billion on capital expenditure this year, much of it on chips, joined by a rising wave of governments building national “sovereign AI” capacity.
The full-stack expansion. NVIDIA’s market is no longer just GPUs. Its networking business alone exceeded $31 billion in fiscal 2026, with software, robotics, and automotive opening fresh markets stacked on top of the core chip.
The annual product cadence. By shipping a more powerful and more expensive generation every year (Blackwell to Rubin to Feynman), NVIDIA turns a one-time sale into a recurring upgrade cycle.
The China wildcard. Export restrictions have kept NVIDIA largely out of China, but in May 2026 the US Commerce Department cleared about 10 Chinese firms to buy the H200 chip, including Alibaba, Tencent, and ByteDance. Huang has estimated China could be a roughly $50 billion annual opportunity in 2026 if NVIDIA can fully serve it.
For all its complexity, NVIDIA’s business model is relatively simple. It sells the essential ingredients of AI at high margins, and has arranged it so that buying one ingredient pulls in the rest. The result is a company that earns 75 cents of gross profit for every dollar of revenue — a structural dynamic that looks less like a chip maker (e.g. AMD at 53%) and more like a software company. Hardware typically lives on thin margins because ‘hardware is hard’, doubly so in semiconductors. NVIDIA escapes that trap because customers are not paying purely for silicon. They’re paying for performance, and the related software ecosystem, they cannot get anywhere else.
The company sells an expensive razor (e.g. hardware / GPUs) and gives away the blades (e.g. CUDA, model libraries) for free to lock-in customers. A single GPU can cost north of $30,000. But the cost of switching to a cheaper chip is abandoning a decade of software your engineers know by heart. The cherry on top is a deliberate upgrade treadmill: NVIDIA launching new and more expensive chip generations every year (Blackwell —> Rubin —> Feynman) at the same cadence Apple has trained the world to expect from a phone. NVIDIA also generates revenue from its networking solutions, pre-trained models / software frameworks (subscriptions), and full hardware systems such as the DGX racks.
NVIDIA rarely sells directly to the end user of its chips. Instead, it reaches the market primarily through three layers that help multiply its reach beyond what a traditional B2B sales effort could manage:
Hyperscalers. The largest cloud providers (MSFT, AMZN, GOOGL, ORCL) buy NVIDIA hardware in enormous volume and rent it out to end customers by the hour. Combined 2026 capital expenditure plans from Alphabet, Amazon, Microsoft, and Meta now total ~$725 billion (up 77% from 2025’s $410B), according to FT, with a large share of it going to NVIDIA.
System builders + enterprises. Server makers such as Dell, HPE, and Supermicro package NVIDIA chips into finished machines, and a growing number of large enterprises and national governments (sovereign AI buyers) purchase infrastructure to run on-prem. NVIDIA helps support these purchases with reference designs and validated blueprints so that AI data centers are built to a known recipe rather than from scratch.
Developer ecosystem. NVIDIA also puts its tools in the hands of millions of developers / researchers via free software, university programs, and even desk-side machines such as the DGX Spark. The company trains its own future demand: every person who learns to build on CUDA becomes a reason for their employer to purchase NVIDIA hardware down the road.
NVIDIA’s own customers (the hyperscalers) are building their own chips in an effort to verticalize their stacks and cut dependency: Google’s TPU, Amazon’s Trainium, and Microsoft’s Maia are all custom silicon aimed at claw back some of the margin that NVIDIA extracts.
Interestingly, while other chip companies and hyperscalers are building alternatives with more memory, or on better process nodes (e.g. AMD’s MI450 on TSMC’s 2nm process), NVIDIA’s sustained domination illustrates that the moat is not in the chip itself. To understand NVIDIA’s edge, one needs to look past the chips and see the company as a systems / software architect that uses silicon as the delivery mechanism. Even if peer hardware can meet or beat NVIDIA specs on paper, the associated software still requires significant kernel engineering work to close the utilization gap. You can buy a powerful AMD chip and still leave a good portion of its capabilities stranded because the software to fully exploit the hardware is less mature than NVIDIA’s. A faster engine does not help if half the cylinders are hard to fire. This produces a counterintuitive economic result, where NVIDIA is simultaneously both the premium-priced option, and the cheaper one in the long-term.
The key factors behind the company’s defensibility stems from:
Software Ecosystem: Every framework, tutorial, and trained engineer assumes CUDA so the cost of switching relates not only to the chip, but the cost of retraining the workforce + rewriting the working code.
Systems Integration: NVIDIA no longer sells just the chips — it sells matched racks where the GPU, CPU, networking and software are all co-designed to work together.
Pace of Work: NVIDIA is shipping a new architecture every year. Competitors who catch up to this year’s chip are already a year behind on the next one. Hitting a target is hard enough, but hitting one that keeps moving requires completely different calculus.
Interconnect / Networking: As GPU clusters grow, the bottleneck shifts from compute speed to how fast data is shared. NVIDIA addresses this inside the rack via NVLink, between racks via Spectrum-X Ethernet, and across datacenters via Quantum-X Infiniband. NVIDIA is now building co-packaged optics (CPO), using third-party suppliers such as Lumentum / Coherent) directly onto the switch chip to reduce power consumption, enhance bandwidth density, and bolster network resiliency.
NVIDIA is led by CEO Jensen Huang, who co-founded the company in a Denny’s in 1993, and has run it since — one of the longest tenures held by any sitting tech CEO. Born in Taipei, he emigrated to the US as a child and earned a BS in Electrical Engineering (EE) from Oregon State before going on to complete a Masters in EE from Stanford. Before NVIDIA, he designed microprocessors at AMD and held a mix of engineering and general management roles at LSI Logic.
Chris Malachowsky (Co-Founder) serves as a Fellow, and has been instrumental in leading multiple functions (e.g. IT, operations, product engineering) from inception. Prior to NVIDIA, he held engineering and technical leadership roles at HP and Sun Microsystems. He holds a BS in EE from the University of Florida, and an MS in CS from Santa Clara University.
Colette Kress (CFO) brings decades of experience to NVIDIA, and has been the financial steward since 2013. She joined from Cisco, where she was the former SVP / CFO of Cisco’s Business Technology and Operations Finance Organization after an earlier stretch at Microsoft as a Corporate VP. She holds an MBA from SMU Cox School of Business.
There are a few cases for upside convexity:
Physical AI becomes a second growth engine.
NVIDIA’s robotics and automotive stack is a rounding error vs. the data center segment, but if physical systems become ‘smart’ and hit commercial scale, NVIDIA owns much of the training-sim-deployment pipeline that few rivals can compete with. This would help extend the growth story beyond the training / inference cycle.
The ability to reuse CUDA, Omniverse, and the existing chip architectures across new end markets with minimal incremental R&D would also imply high incremental margins vs. requiring a separate cost base.
China dollars flow to NVIDIA.
While US x China relations remain complicated, the U.S. government recently cleared sales of NVIDIA’s H200 chips to 10 Chinese firms (e.g. Alibaba, Tencent, ByteDance). Despite approval, Chinese regulators have delayed and restricted purchases to foster their domestic chip ecosystem. At peak, China revenue represented ~13% of sales in FY25 before tight export controls were imposed.
China sales are a call option sitting outside current sell-side estimates; a sustainable policy resolution would be pure upside to consensus, even if the path does run through DC and Beijing.
On downside, the key areas of risk involve:
AI capex deceleration.
The single largest risk is a slowdown in customer spending. NVIDIA’s topline growth is tied to demand from a small set of super customers (hyperscalers) that have increased capex aggressively over the past few years. Any sustained pullback in GPU procurement would send shockwaves through the chip ecosystem, given how much growth is priced in. Current valuation leaves no room for error.
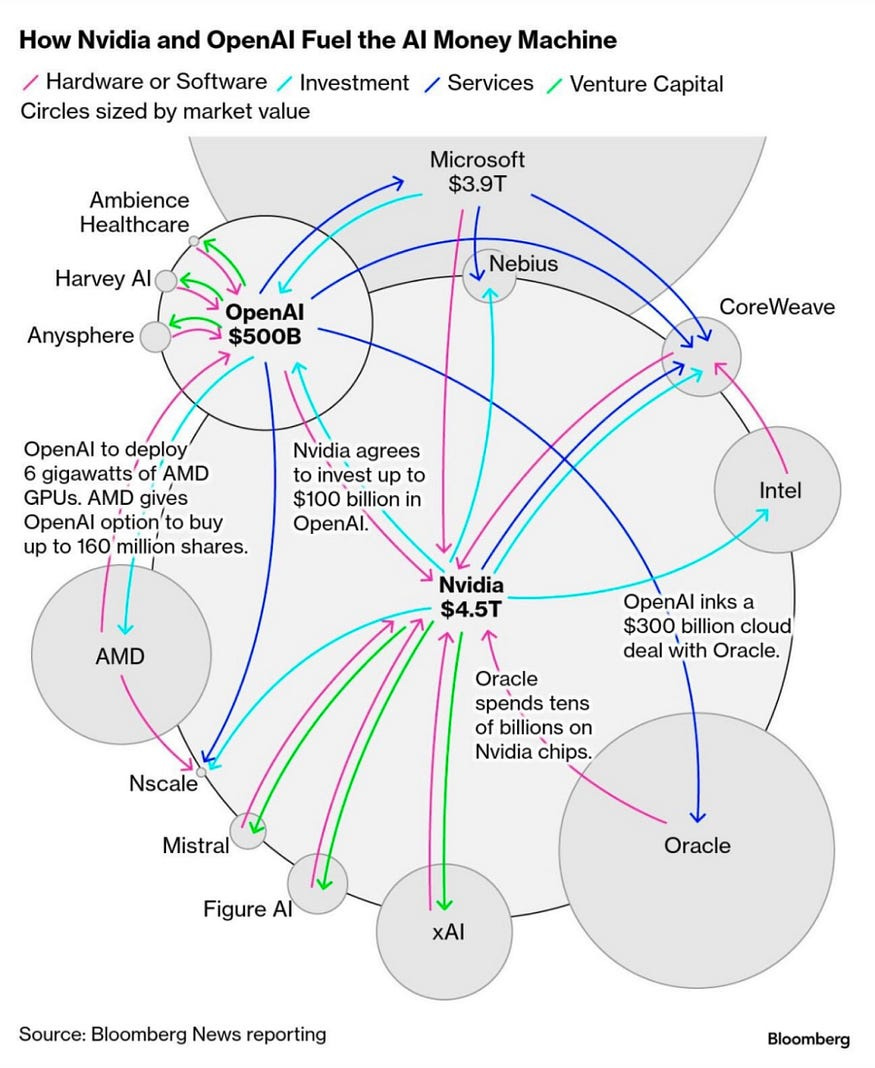
The unwinding of circular financing.
NVIDIA has vested interests in a number of companies within the AI ecosystems (e.g. stakes in foundation model companies, neoclouds). The cash NVIDIA invests is roundtripped back to NVIDIA through GPUs that fill up the data centers.
The distinction between flywheel and house of cards boils down to the sustained degree of real end-user demand. A report from MIT Media Lab found that 95% of organizations are not seeing any ROI on generative AI spend.
The customer-as-competitor dynamic.
The hyperscalers are building their own chips (Google TPUs, Amazon Trainium, Microsoft Maia), and only need to build a ‘good enough’ chip to bring the most predictable, high-volume workloads in-house, clawing back some of the revenue built into current NVIDIA topline forecasts.
The threat is more of a slow-moving grey swan vs. a black swan event, but it directly threatens market share, especially as these efforts may lead to third-party monetization as well. For example, Google plans to commercialize its TPUs to a ‘select group of customers’ for deployment in data centers.
Disclaimer: This content is for informational and educational purposes only and does not constitute investment advice, a recommendation, or an offer to buy or sell any security. The views expressed are those of the author and are based on publicly available information believed to be reliable, but accuracy and completeness are not guaranteed. Readers should conduct their own research and consult a licensed financial advisor before making any investment decisions. The author may hold positions in the securities discussed. Past performance is not indicative of future results.
Hypothesis is a new platform for individual investors who take their portfolios seriously. We’re building AI-native research and discovery — personalized to how you actually invest, with insights, context, and a community designed for people who do their own work.
Beta launching soon.
Join the waitlist here for early access.